Six things it does well.
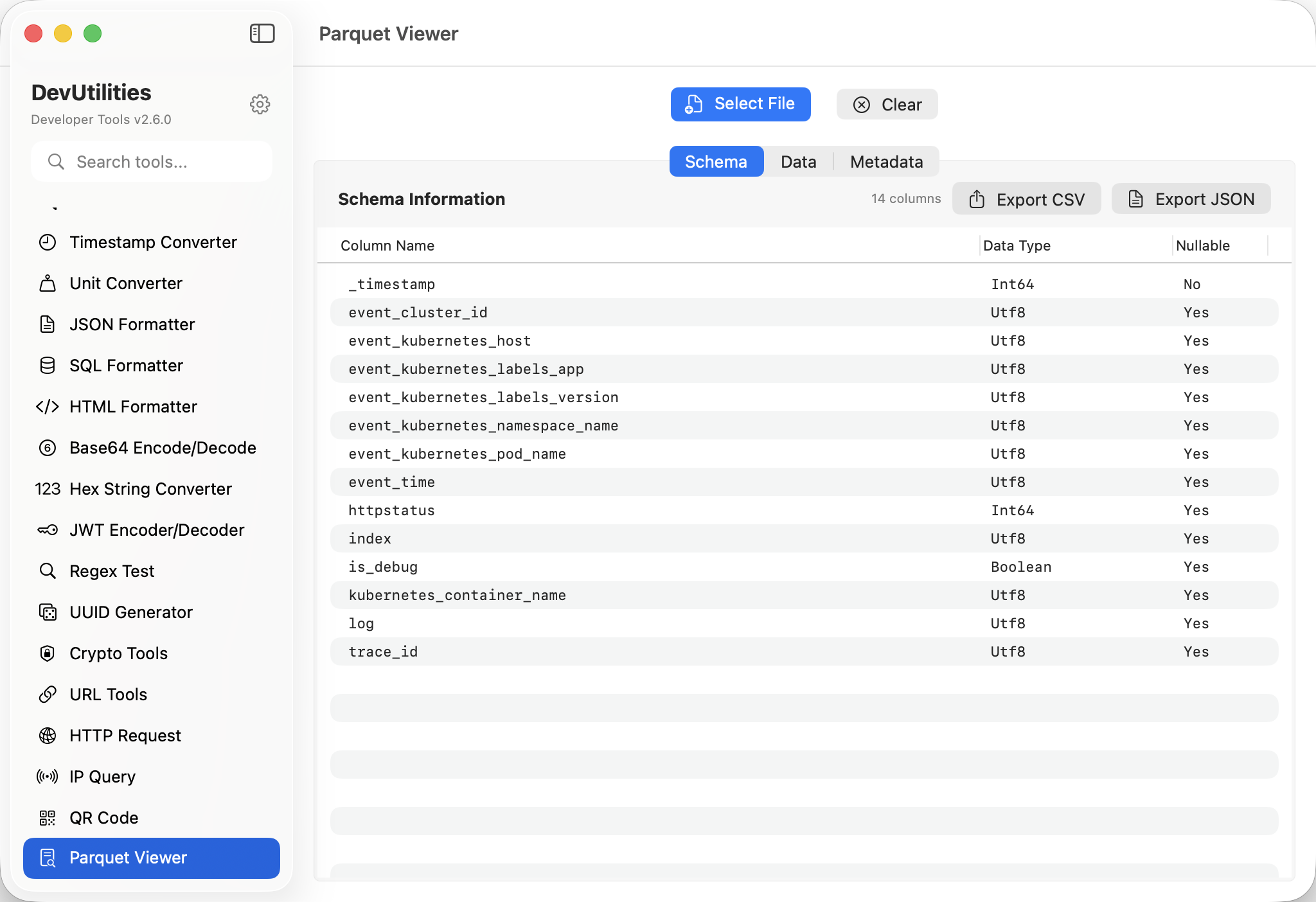
Schema inspection
Field names, types, nesting. The structure of the file, in one panel.
Row preview
Browse rows in a table view. Pagination keeps memory polite even on multi-million-row files.
Parquet & Arrow
Both formats handled by the same Rust core. Drop a .parquet or .arrow and it opens.
Export to JSON
Convert rows to JSON for further processing in JSON, jq, or anywhere else.
Fast loads
Direct JSON output from Rust skips marshalling overhead — first row visible quickly, even on big files.
Drag & drop
Drag a file from Finder onto the panel; it opens.
Four moves through a Parquet file.
Open the file
Drag a Parquet or Arrow file onto the panel.
Read the schema
Field names and types tell you what's inside.
Browse rows
Scroll the table; click a cell to see the full value.
Export
Pull rows out as JSON for downstream work.
The work it actually does.
Pipeline debugging
Open the file your Spark / Pandas pipeline just produced; verify the schema and a few rows.
Drift detection
Compare the schema you got with the schema you expected. Missing columns surface immediately.
Quick samples
Grab a hundred rows for a doc, an issue reproduction, or a colleague's review.
To JSON
Export to JSON for ingestion by tools that don't speak Parquet natively.
Storage layout
Inspect column types and nesting before merging into a downstream warehouse.
Test fixtures
Open a fixture that's part of an integration test and confirm it's still right.
Things people ask before they download.
Which formats are supported?
Parquet (.parquet) and Arrow (.arrow / .feather) — the same Rust core handles both.
How big can the file be?
Practically, gigabytes. The viewer streams rows on demand; nothing tries to load the entire file at once.
Can I run SQL against the file?
The current release focuses on schema and row inspection plus JSON export. The lighter footprint means a fast load and a clean UI; SQL has been intentionally factored out.
What's nesting handling like?
Nested structs and lists are displayed inline; click into a cell to expand and read.
Are file contents stored anywhere?
No. Files are read from local disk on demand. Nothing leaves the machine.
Why a Rust core?
Speed and a single dependency surface. The same engine powers SQL formatting, so DevUtilities pulls in one backend, not two.